Outlier Calculator
Welcome to Omni's outlier calculator, where we'll not only define outliers but also learn what is the meaning of outliers in statistics. In essence, whenever we need to analyze a dataset, we often turn to various statistical tools, and our today's hero is one of them. The outlier definition in math lets you determine if your data has any entries that significantly differ from the others.
So what is an outlier, and how to find them? What is the outlier formula?
Let's jump straight into the article and find out!
What is an outlier?
Quite often, when we have a sequence of entries that describe whatever it is that we're studying, some of the data are significantly smaller or larger than the others. It may be because there is a mistake in the calculations or because the sample was faulty, to begin with. Either way, it's useful to pick out these few entries that distort the results and double-check them.
The values that we've mentioned above are what we call outliers in statistics. They are specific entries of the dataset that are far away from the others. If you want, you can intuitively think of them as significantly different from the average, although it takes a bit more than that to define outliers. We'll get into specifics in the dedicated section.

For now, however, just to give you a taste of the meaning of outliers in statistics, let's imagine a scenario in which a company hires, say, thirty people that do a very similar job. Once the results of the previous months come in, the ones in charge get a table with how much each employee has done.
When we look at so much data in one array, it may be difficult to notice any individuals who deviate from the norm. However, if we were to put all the numbers in a tool such as Omni's outlier calculator, we'd know straight away who struggled with the tasks and who worked harder and would perhaps deserve a raise.
Hopefully, we managed to convince you that it's useful to learn the outlier math definition. Still, so far, we've only seen the descriptive one. Before we introduce the formal, we need a few statistical notions that will appear later in the outlier formula. Fortunately, we can pack them all together in the so-called five-number summary and its corresponding box-and-whiskers plot.
Five-number summary: the box-and-whiskers plot
Raw data is challenging to work with. If, as in the scenario from the previous section, we get thirty or more values, it's difficult to say anything useful about them as a whole. That is where the five-number summary comes in.
In short, the five-number summary gives us a rough idea of how "scattered" the dataset is. For instance, it can tell you whether the middle value is far from halfway between the smallest and largest values. Also, it shows where (with respect to the minimal and maximal entries) a majority of data falls.
Before we mention what the five values are, it'd be useful to mention the box-and-whiskers plot. It is a neat visual representation of the five-number summary in the form of something like this:
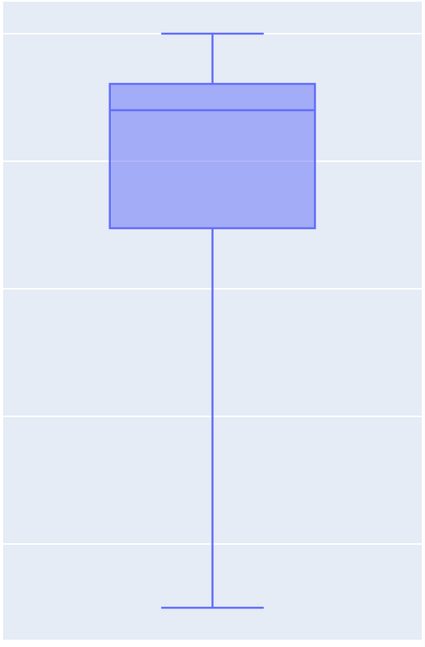
If you work your imagination, the picture should resemble a box (that one makes sense) with a cat's whiskers (that one... well, decide for yourself). Oh, don't laugh at mathematicians' imagination. They don't go out much. Anyway, you can discover more about this concept by going to Omni's box plot calculator.
The five-number summary consists of:
- maximum;
- third quartile;
- median;
- first quartile; and
- minimum.
In the picture, they are marked by the horizontal blue lines consecutively from top to bottom.
The maximum and minimum are, we hope, fairly straightforward - they're the largest and smallest values, respectively. The median is the mid-value in the dataset, i.e., what falls in the middle when we order the entries from smallest to largest. (Note that if we have an odd number of entries, then the median is the one in the middle. However, if we have an even number, it is the mean of the two mid ones.) Lastly, the quartiles are the medians of the smallest (for the first quartile) and the largest (for third) half of the entries.
With all these new definitions, we can read off quite some information from the picture above. For instance, we see that the middle half of the entries, i.e., those between the first and third quartile (given by the blue box), are fairly close to the maximum. This interval is often called the interquartile range and will become quite useful in the outlier formula.
🔎 If any of the notions mentioned above is new to you and you feel a bit lost, don't hesitate to pay a visit to one of our dedicated tools:
Also, we can observe that the minimum is quite far from the box. It does seem like there should be some outliers, doesn't it?
Indeed this gives an excellent representation of outliers on the boxplot: they are values that are far from the interquartile range. Therefore, we get one more reason why it's simpler to analyze a dataset with the five-number summary and the box-and-whiskers plot instead of the raw sequence of values.
However, we still haven't seen the outlier formula, so we're yet to learn what "far" means in this context. But with all the necessary definitions behind us and the connection between the boxplot and outliers, we're more than ready, aren't we?
How to find outliers: the outlier formula
As we've mentioned in the above section, the outlier definition in math requires a few other values connected with the dataset. Let's begin with the notation:
Q1 = 1st quartile,
Q3 = 3rd quartile,
IQR = Q3 − Q1 = interquartile range.
Note how we use only two elements from the five-number summary. However, to calculate the quartiles, we need to know the minimum, maximum, and median, so in fact, we need all of them.
With that taken care of, we're finally ready to define outliers formally.
💡 An outlier is an entry x which satisfies one of the below inequalities: x < Q1 − 1.5 × IQR or x > Q3 + 1.5 × IQR.
We have finally learned what "far" from the last paragraphs of the above section meant: it means at least 1.5 * IQR away from the corresponding quartile.
These thresholds are commonly called the dataset's upper and lower fences.
Note, however, that if the dataset is dense, i.e., the entries are not too scattered, then it may happen that there are no outliers. In practice, when conducting statistical research, this is often a good thing. It can mean that the model we're trying to apply (e.g., approximate the data with a normal distribution) is accurate.
Now, what would you say if we told you that this was the last bit of theory in this article? Oh, a sigh of relief is in place, alright. But don't leave us just yet! We've learned the meaning of outliers, so it's time to use it in an example.
Example: using the outlier calculator
Say that due to social distancing and all the restrictions, your gym teacher had a brilliant idea to make today's class a bench pressing "tournament." Some of the kids are excited, some are disappointed, and some look scared. Nevertheless, everyone needs to try it out.
One by one, you step in to have a go, and the teacher meticulously notes the weights. After all twenty-one students are done, their results (in pounds) are:
32, 42, 40, 38, 44, 60, 58, 50, 32, 44, 62, 96, 48, 46, 54, 66, 78, 80, 94, 40, 60.
Quite a range, isn't it? The teacher seems satisfied with the results or, at least, with their idea for the lesson. Even better - they decide to analyze the data and, after dismissing class, approaches the math teacher for help. Together they sit down at the small school desks to do some calculations and check for any outliers.
(Fair enough, the scenario may sound a little far-fetched... But there must have been some worse ones in your textbooks, right?)
First of all, let's see how easily and quickly the teachers would find the results if they used Omni's outlier calculator. In it, we see variable fields where we input the entries one by one. Note how initially the calculator shows only eight fields, but new ones appear whenever you seem to reach the limit (in fact, you can enter up to thirty numbers).
Once we input the last one, we scroll down to the graph (a simplified version of the box-and-whiskers plot) with our data. Observe how the outlier calculator shows a chart already for two numbers, and the graph changes with every added number.
In the picture, we can see lines that mark the five-number summary. (Additionally, if you'd like, you can go to the advanced mode and choose "Yes, please." under "5-number summary?" to have the five numbers listed under the variable fields.) However, what interests us most are the red and yellow dots that mark our entries - they are the boxplot outliers and non-outliers, respectively. Also, the calculator lists all the outliers under the chart or shows a message if there are none.
Well, that was effortless. Still, let's do a little of bench-pressing ourselves (or something alike, at least) and see how to find the outliers ourselves.
First of all, we'll need to order our dataset. (Observe how when we input the numbers into the outlier calculator, it does it for us and gives us the ordered list underneath.) That means that the initial list:
32, 42, 40, 38, 44, 60, 58, 50, 32, 44, 62, 96, 48, 46, 54, 66, 78, 80, 94, 40, 60,
becomes:
32, 32, 38, 40, 40, 42, 44, 44, 46, 48, 50, 54,58, 60, 60, 62, 66, 78, 80, 94, 96.
Next, we'll need to find the minimum, maximum, median, and outliers. The first two are the simplest - they're the first and last entry in the sorted list, i.e.,
minimum = 32, maximum = 96.
Now, we calculate the median. We have twenty-one values, so it will be the eleventh entry of the ordered list since it has ten (smaller) numbers to the left and ten (larger) to the right. Therefore,
median = 50.
Lastly, we need the quartiles, which, by definition, are medians of the smaller and larger half of the values for the first and third quartile, respectively. Note that since we have twenty-one entries, in each case, we'll take eleven of them with the middle one (the median) repeating in both sequences.
In our case, the first quartile will be the sixth value in the ordered list (since among the first eleven, it has five numbers to the left and five to the right), and the third quartile will be the sixteenth (as above but for the last eleven entries). That translates to
Q1 = 42, Q3 = 62.
Phew, that may have been tiring. Fortunately, from now on, we're left with easy calculations only. (Not that the previous ones were tricky. Still, they required more thinking than simple addition, which comes next.)
If we recall the outlier formula from the previous section, we'll see that we need the interquartile range.
IQR = Q3 - Q1 = 62 - 42 = 20.
Lastly, we need to determine the limits for the outliers. According to the outlier definition in math, in our case, an entry x is an outlier if either
x < Q1 - 1.5 * IQR = 42 - 1.5 * 20 = 42 - 30 = 12
or
x > Q3 + 1.5 * IQR = 62 + 1.5 * 20 = 62 + 30 = 92.
When we look at our entries, we see that we have no values smaller than 12, but there are two larger than 92: 94 and 96. In other words, we have two outliers, i.e., two numbers that are significantly larger than the rest.
Come to think of it, they must have been the two athletic kids that regularly train in wrestling. Well, they certainly deserve to be called champions of the tournament!